Project completed in week 7 (09.11.-13.11.20) of the Data Science Bootcamp at Spiced Academy in Berlin.
This week’s project was the most complex and difficult so far. The challenge was to create a database of tweets, along with their sentiment score, and post positive tweets in a Slack channel. This pipeline had to be orchestrated with Docker Compose. Here’s my quick and messy hand-drawn schema of the pipeline:
 Schema of the ETL pipeline
Schema of the ETL pipelineIn this post, I’ll show you how I set up each step.
| Note that the purpose of this project was mainly educational, giving the bootcamp students the opportunity to learn and work with different tools. There are probably more efficient ways of achieving the same result (for example, using only one database). |
Table of contents
0. Prerequisites & tech stack
1. Collecting tweets
2. Storing tweets in MongoDB
3. Performing ETL job
3.1. Extracting tweets from MongoDB
3.2. Transforming tweets with sentiment scores
3.3. Loading tweets into PostgreSQL
4. Extracting tweets from Postgres
5. Posting tweets with a Slackbot
6. Creating the Docker Compose pipeline
Friday Lightning Talk
0. Prerequisites & tech stack
Here’s an overview of the apps, services, and libraries I used in this project:
| Apps & Databases | Python libraries |
|---|---|
tweepy & vader |
|
| Slack | slackclient |
| MongoDB | pymongo |
| PostgreSQL | psycopg2-binary & sqlalchemy |
| Docker-Compose | - |
1. Collecting tweets
To collect tweets, I used the Twitter API along with the tweepy library.
First, I created an app on Twitter and got my credentials (API key and Access Token). Then, I wrote the Python code for streaming live tweets, using tweepy with my Twitter credentials. I chose to stream the hashtag #OnThisDay (thought it would be interesting to get a daily notification of what happened years ago) and collected the tweet text and user handle.
from tweepy import OAuthHandler, Stream, API
from tweepy.streaming import StreamListener
tweet = {
'username': t['user']['screen_name'],
'text': t['text'],
}
stream_listener = StreamListener()
stream = tweepy.Stream(auth=api.auth, listener=stream_listener)
stream.filter(track=['OnThisDay'])
2. Storing tweets in MongoDB
After collecting the tweets, I had to store them in MongoDB, a non-relational (NoSQL) database that stores data in JSON-like documents. Since the tweet data is collected as key-value pairs (JSON format), MongoDB is a good way to store this information.
First, I had to create a MongoDB instance, set up a cluster, and create a database and a collection within it:
- Create a MongoDB account
- Set up a cluster: cloud.mongodb.com > Clusters > Create New Cluster
- Create a database: Cluster > Collections > Create Database
- Create a collection: Cluster > Collections > Database > Create Collection
- Create a field: Collection > Insert document > Type the field
textbelow_id - Allow access to the database: Project > Security > Network Access > IP Access List > Add your IP address.
- Connect to the database from your terminal:
mongo "mongodb+srv://YourClusterName.mongodb.net/YourDatabaseName" --username YourUsername
Second, I wrote the Python code for storing tweets in MongoDB using the pymongo library.
import pymongo
client = pymongo.MongoClient(host='mongo_container', port=27018)
db = client.tweets_db
def warning_log(tweet):
logging.critical('\n\nTWEET: ' + tweet['username'] + 'just tweeted: ' + tweet['text'])
db.collections.onthisday.insert_one(tweet)
The host mongo_container is one of the Docker containers, explained in section 5.
3. Performing ETL job
The ETL (Extract, Transform, Load) job involves three actions: extracting tweets from MongoDB, analyzing their sentiment, and storing them into a new Postgres database. Here is the Python code for the ETL job.
3.1. Extracting tweets from MongoDB
To extract the tweet texts from MongoDB, I used again the pymongo library.
def extract_tweets():
tweets = list(db.onthisday.find())
if tweets:
t = random.choice(tweets)
logging.critical("Random tweet: "+t["text"])
return t
3.2. Transforming tweets with sentiment scores
To analyze the sentiment of the tweets, I used the VADER library , which returns (among others) a compound sentiment score.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
def transform_tweets(tweet):
tweet_text = tweet['text'].replace("\'","")
sia = SentimentIntensityAnalyzer()
tweet_sia = sia.polarity_scores(tweet_text)['compound']
return tweet_sia
3.3. Loading tweets into PostgreSQL
To load the tweets with their sentiment scores into a Postgres database, first you need––well, a Postgres database. I installed Postgres, then created a database and a table for tweets right from the terminal:
- Connect to Postgres:
psql - Create a database:
createdb twitter - Go into the created database:
psql twitter - Create columns in the database:
CREATE TABLE tweets (text varchar(280), score numeric(4,3);
Then, I wrote the Python code for inserting tweets into the tweets table, using the sqlalchemy library.
def load_tweets(tweet, sentiment):
insert_query = """
INSERT INTO tweets VALUES ('{tweet["text"]}', {tweet_sia});
"""
engine.execute(insert_query)
logging.critical(f'Tweet {tweet["text"]} loaded into Postgres.')
4. Extracting tweets from Postgres
After having a database of tweets and their sentiment score in place, I had to select and extract some tweets, that would be sent to Slack.
query = pg.execute(
"SELECT text FROM tweets ORDER BY sentiment DESC LIMIT 1")
msg = str(list(query))
output = f'NEW TWEET! {user} just tweeted: {msg} \nSentiment score: {blob_score}'
5. Posting tweets with a Slackbot
The last step in the pipeline is posting tweets in a Slack channel. To do this, first I created a Slackbot.
Then, I wrote the Python code for posting tweets in a Slack channel, including the code from the previous step:
import time
import slack
from sqlalchemy import create_engine
import config
engine = config.PG_ENGINE
webhook_url = config.WEBHOOK_SLACK
while True:
logging.critical("\n\nPositive tweet:\n")
query = pg.execute(
"SELECT text FROM tweets ORDER BY sentiment DESC LIMIT 1")
msg = str(list(query))
logging.critical(msg + "\n")
output = f'NEW TWEET! {user} just tweeted: {msg} \nSentiment score: {blob_score}'
data = {'text': output}
requests.post(url=webhook_url, json=data)
time.sleep(30)
And :tada: –– here’s the tweet that was posted in Slack:
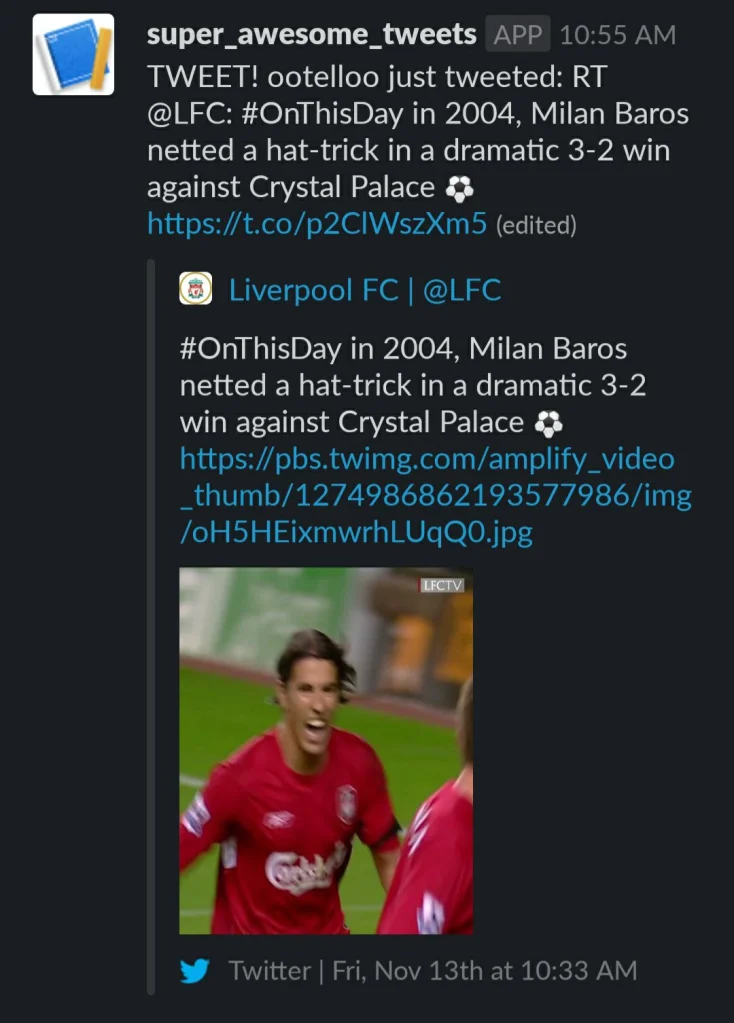 Tweet posted by Slackbot
Tweet posted by Slackbot6. Creating the Docker Compose pipeline
The final touch of this project is orchestration. The individual Python scripts for each step work when you run them manually, but the goal is to run this pipeline from beginnning to end with only one command. This is where Docker Compose comes in.
Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file to configure your application’s services. Then, with a single command, you create and start all the services from your configuration.
Each of the five previous steps (or the rectangles in my messy schema) represents a Docker container, so in my docker_compose.yml file I had five containers (services): tweet_container, postgres_container, mongo_container, etl_container, and slackbot_container.
For the two database containers, I used Docker images, since they didn’t depend on custom code stored in my project folders. For the other three containers, I referefenced the respective code location (build) and their dependencies (depends_on) (for example, the tweet_collector depends on postgres and mongo, since the tweets are stored in these databases).
I also used Docker volumes to keep the data when the containers are stopped (data persistence).
version: '3'
services:
tweet_container:
build: tweet_collector/
depends_on:
- postgres_container
- mongo_container
volumes:
- ./tweet_collector/:/app
postgres_container:
build: postgresdb
image: postgres:13.0
ports:
- 5555:5432
environment:
- POSTGRES_USER=your_user
- POSTGRES_PASSWORD=your_password
mongo_container:
build: mongodb
image: mongo
ports:
- 27018:27018
volumes:
- ./mongodb:/app
etl_container:
build: etl_job/
depends_on:
- postgres_container
- mongo_container
volumes:
- ./etl_job/:/app
slackbot_container:
build: slackbot/
depends_on:
- mongo_container
- postgres_container
volumes:
- ./slackbot/:/app
Finally, here some of the CLI commands I used for managing the Docker containers (you can find more in their docs):
docker imagesto list all the used images (postgres and mongo)docker ps -ato list all my containersdocker -vto mount volumesdocker buildto build an image from a Docker filedocker runto run the containers
And that was it: my very first dockerized ETL pipeline –– a week’s work and a few hours writing packed in a 6-minute blog post.
Friday Lightning Talk
This week I focused on the Transform part of the project, which was about Sentiment Analysis. When we learned about the VADER library, some colleagues asked how the training data is collected and who rates the training texts. To answer these questions, I decided to present one of my dearest personal projects in which I did exactly that: I created a list of emotion verbs and asked native speakers to rate their valence, arousal, and duration. You can read more about this project (and data analysis) on GitHub and in this blog post from a student conference.