It’s no secret (anymore) that data is precious. Structured data is particularly valuable for companies and professionals in pretty much any industry, as it offers them the raw material for making predictions, identifying trends, and shaping their target audience.
One method for getting hold of structure data, that has been growing in popularity in the past ten years, is web scraping. In this post, we’ll explain the basics of web scraping and show you a step-by-step tutorial for building an n8n workflow that scrapes data from an online store.
What is web scraping?
Web scraping (also called web harvesting) is the process of automatically extracting and collecting data from a website. This is a useful approach if you need to get structured data from a website that doesn’t have an API, or if the API offers limited access to the data.
In practical terms, let’s say you want to have a spreadsheet with data about the top 50 bestselling products in an online store, including product name, price, and availability. One option is to manually copy-paste the data from the website into the spreadsheet – but this would be incredibly time-consuming and error-prone. Alternatively, you can automatically collect this data using web scraping.
Can you scrape data from any website?
Not really. Some websites explicitly prohibit web scraping, while others allow it, though they might also limit what data you can collect. To check whether the website you want to scrape allows this, have a look at their robots-txt file. You can access it by appending this file name to the domain name. For example, to check whether IMDb allows web scraping, go to https://imdb.com/robots.txt.
The robots.txt file instructs search engine crawlers which URLs they can crawl. Restricting crawling on certain pages avoids overloading the website with requests. This is important, because when doing web scraping, you’re basically sending lots of requests to the website in a short time interval, thus overloading it and impacting its performance.
In the case of IMDb, their robots.txt file doesn’t allow scraping content from pages like TV schedule, movies, and many others.
While web scraping is not illegal, it’s a grey area. You can get sanctioned, banned or blocked from the website, or fined if you scrape data from certain websites and/or commercialize it. To make sure you’re on the right side of the law, always check the robots.txt file of the website you want to scrape.
How does web scraping work?
Essentially, the web scraping process involves 5 steps:
- Select the URL (website) you want to scrape.
- Make a request to the URL. The server responds to the request and returns you the data in HTML or XML page.
- Select the data you want to extract from the webpage.
- Run the code to extract the selected data.
- Export the data in a readable format (for example, as a CSV file).
How to do web scraping?
Nowadays, there are different options to do web scraping, from browser extensions to no-code tools and custom code in different programming languages. Here are three ways to do web scraping, with their advantages and downsides.
Using browser extensions or tools
Browser extensions are the easiest way to do basic web scraping. If you’re not particularly tech-savvy or only need to scrape some data quickly from a static page, you can reach out for tools like Parsehub, Octoparse, or Webscraper.io.
The downside of browser extensions like these is that they usually have limited functionality (for example, they might not work on pages with dynamic loading or websites with pagination). Moreover, some tools are paid or freemium, and it can get quite costly if you need to scrape lots of data.
Using custom code and web scraping libraries
If you know how to code, you can use libraries dedicated to web scraping in different programming languages, such as rvest in R, or BeautifulSoup, ScraPy, and Selenium in Python. For example, you can scrape and analyze movie information using rvest or music lyrics using BeautifulSoup.
The advantage of using libraries like these is that you have more flexibility and control over what you scrape and how to process data – plus it’s free. The downside to this approach is that it requires programming skills, and writing custom code can be time-consuming or become overly complicated for a basic scraping use case.
Using n8n workflows
n8n combines the power of libraries with the ease of browser extensions –– and it’s free to use. You can build automated workflows using core nodes like HTTP Request and HTML Extract to scrape data from websites and save it in a spreadsheet.
Moreover, you can extend the workflow however you like, for example by emailing the spreadsheet, inserting the data into a database, or analyzing and visualizing it on a dashboard.
Workflow for web scraping
Let’s build a web scraper with no code using n8n!
This workflow scrapes information about books from the fictive online book store http://books.toscrape.com, stores the data in Google Sheets and in a CSV file, and emails the file.
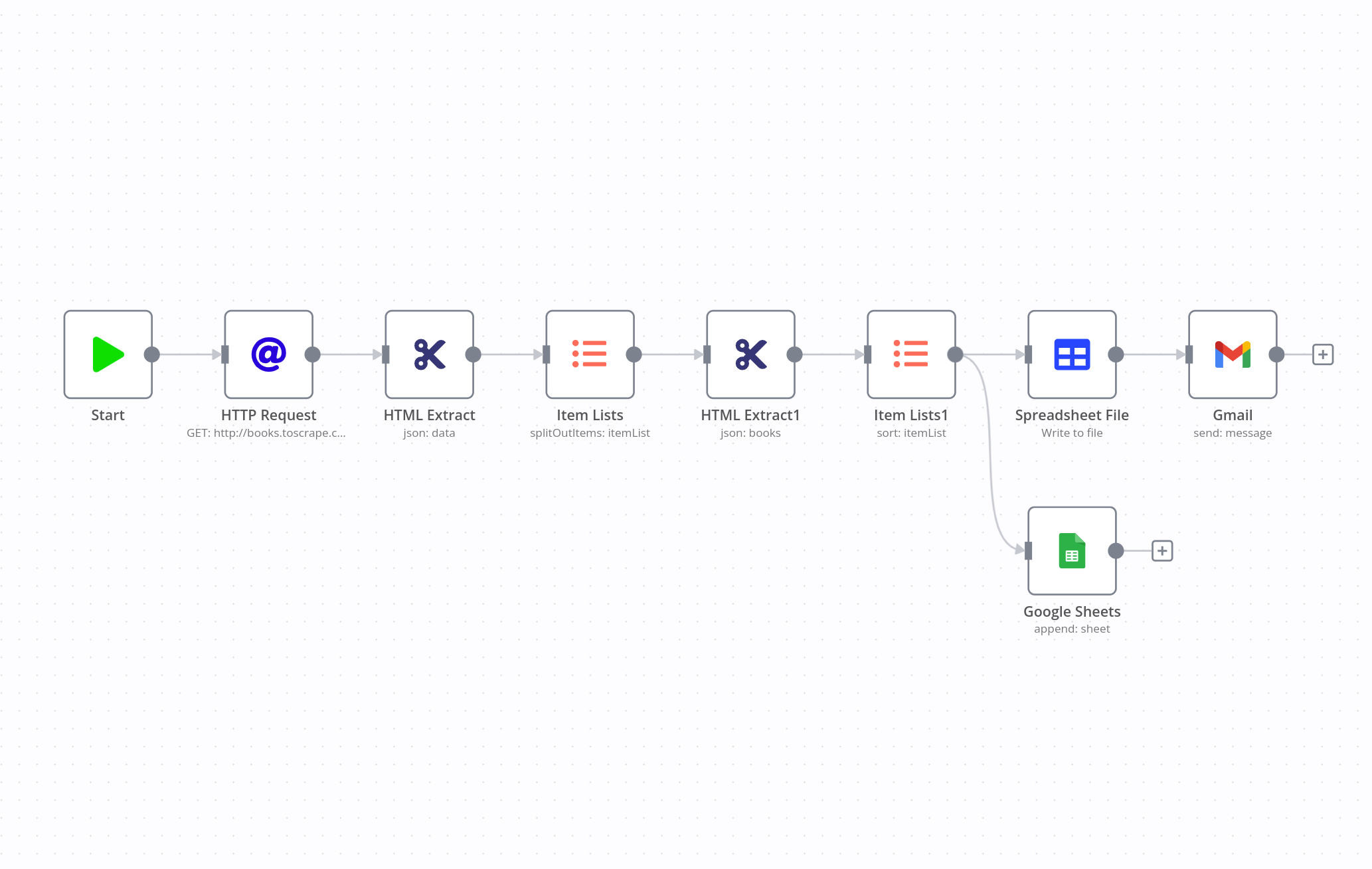
The workflow makes use of three core nodes and two Google nodes, and consists of five steps:
- Access the content of the website (HTTP Request node).
- Scrape the title and price of books (HTML Extract node).
- Order the scraped data alphabetically by title (Items Lists node).
- Write the scraped ordered data into a CSV file (Spreadsheet node) and append it to a Google Sheet (Google Sheet node).
- Send the CSV file via email (Gmail node).
Next, you’ll learn how to build this workflow with step-by-step instructions.
Prerequisites
- n8n set up. The easiest way is to download the desktop app, but you can also sign up for n8n.cloud or self-host n8n.
- Basic knowledge of HTML and CSS. This is helpful for knowing how to navigate the webpage and what elements to select for the data you want to extract.
- A Gmail account and credentials. Alternatively, you can use the Send Email node or nodes for other email providers (Mailcheck, MailChimp, MailerLite, Mailgun, Mailjet).
Step 1 - Getting the website content
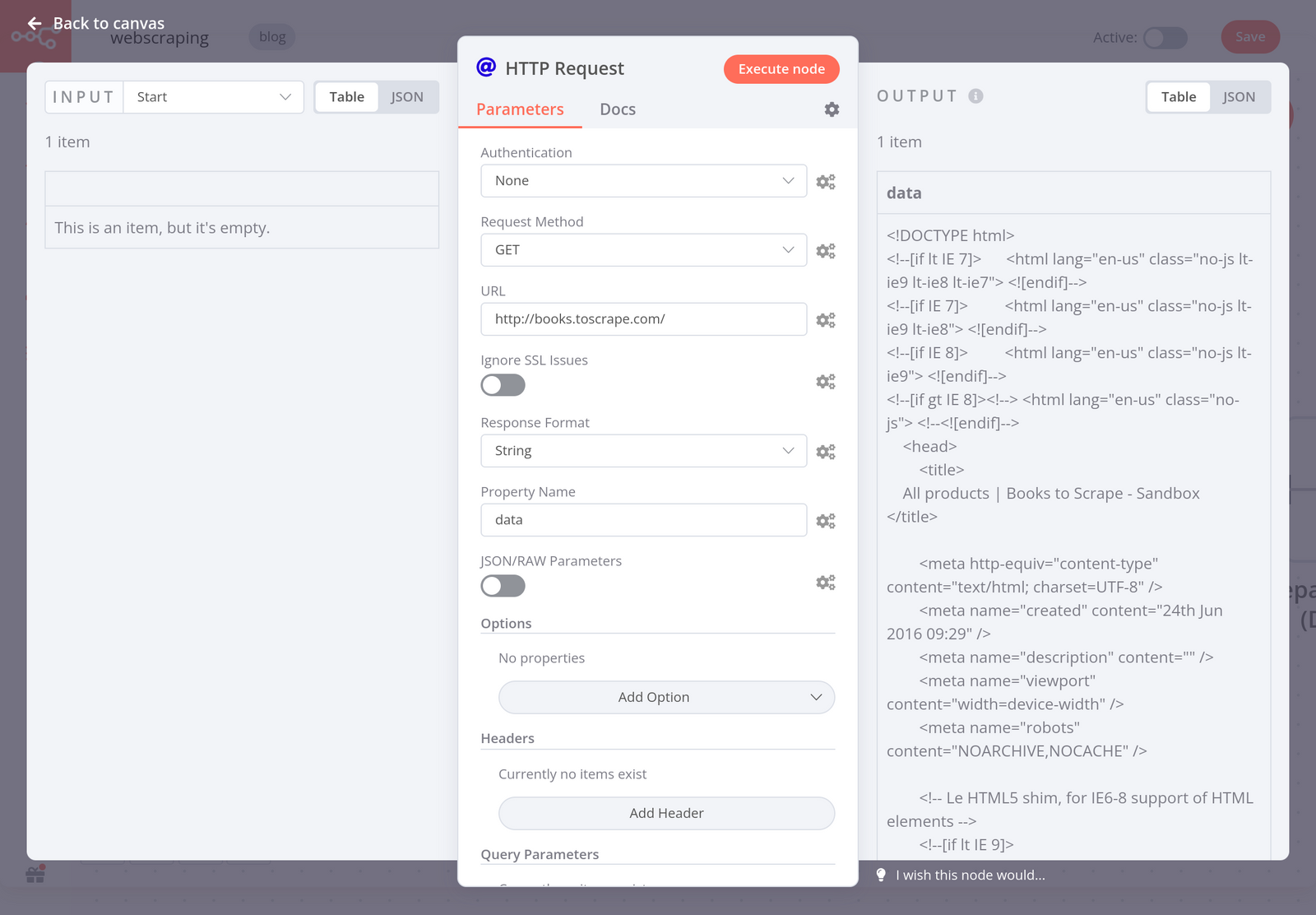
First of all, you need to get data from the website in HTML format. To do this, use the HTTP Request node with the following parameters:
- Request Method: GET
- URL: http://books.toscrape.com
- Response Format: String
- Property Name: data
When you execute the node, the result should look like this:
Step 2 - Extracting data from the website
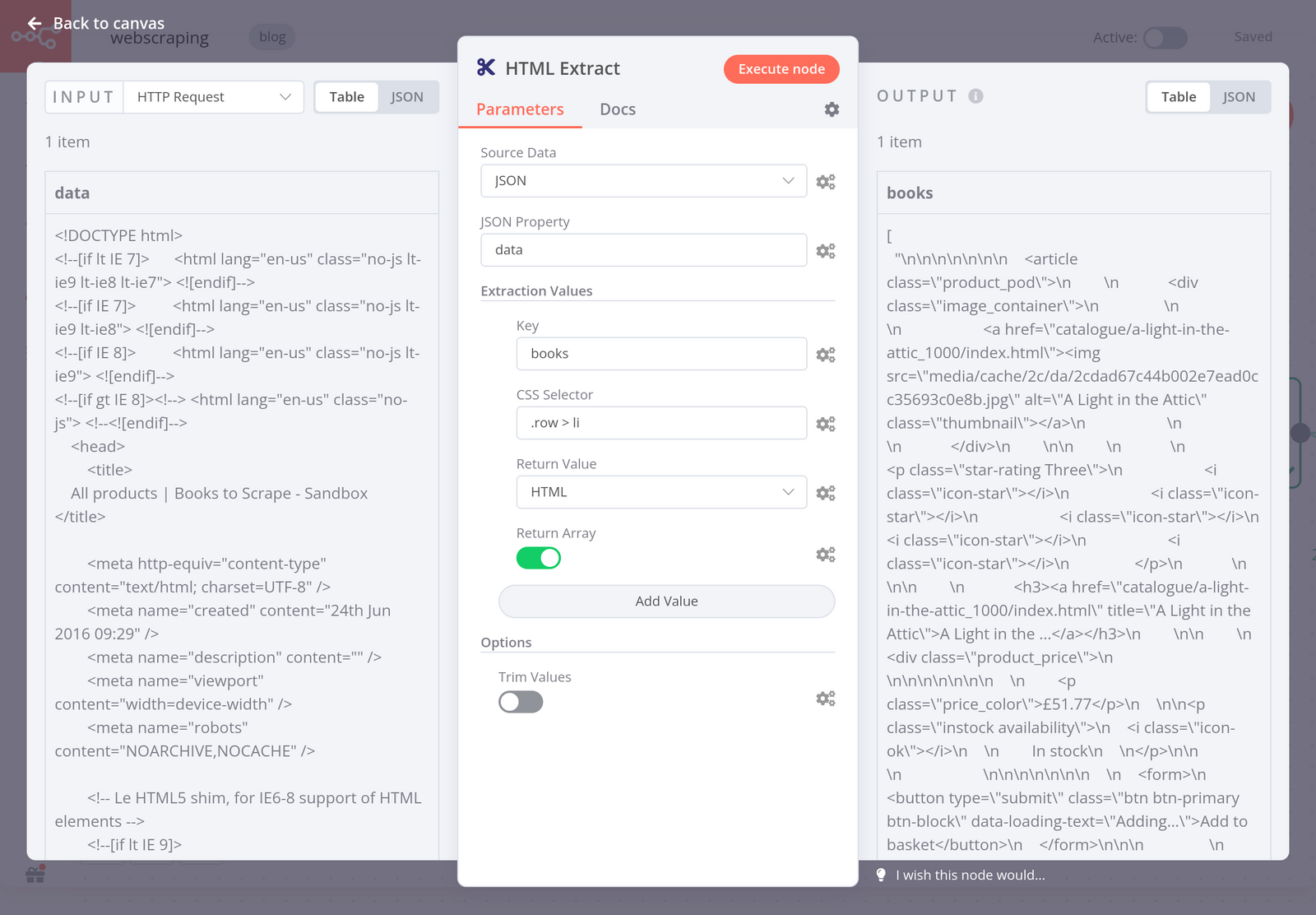
Now that you have the HTML code of the website, you need to extract the data you want (in this case, all the books on the page). To do this, use the HTML Extract node with the following parameters:
- Source Property: JSON
- JSON Property: data This is the property name set in the HTTP Request node.
- Extraction Values:
- Key: books
CSS Selector: .row > li
To get the selector (the reference of the data you want to extract), inspect the page in your browser.
- Key: books
When you execute the node, the result should look like this:
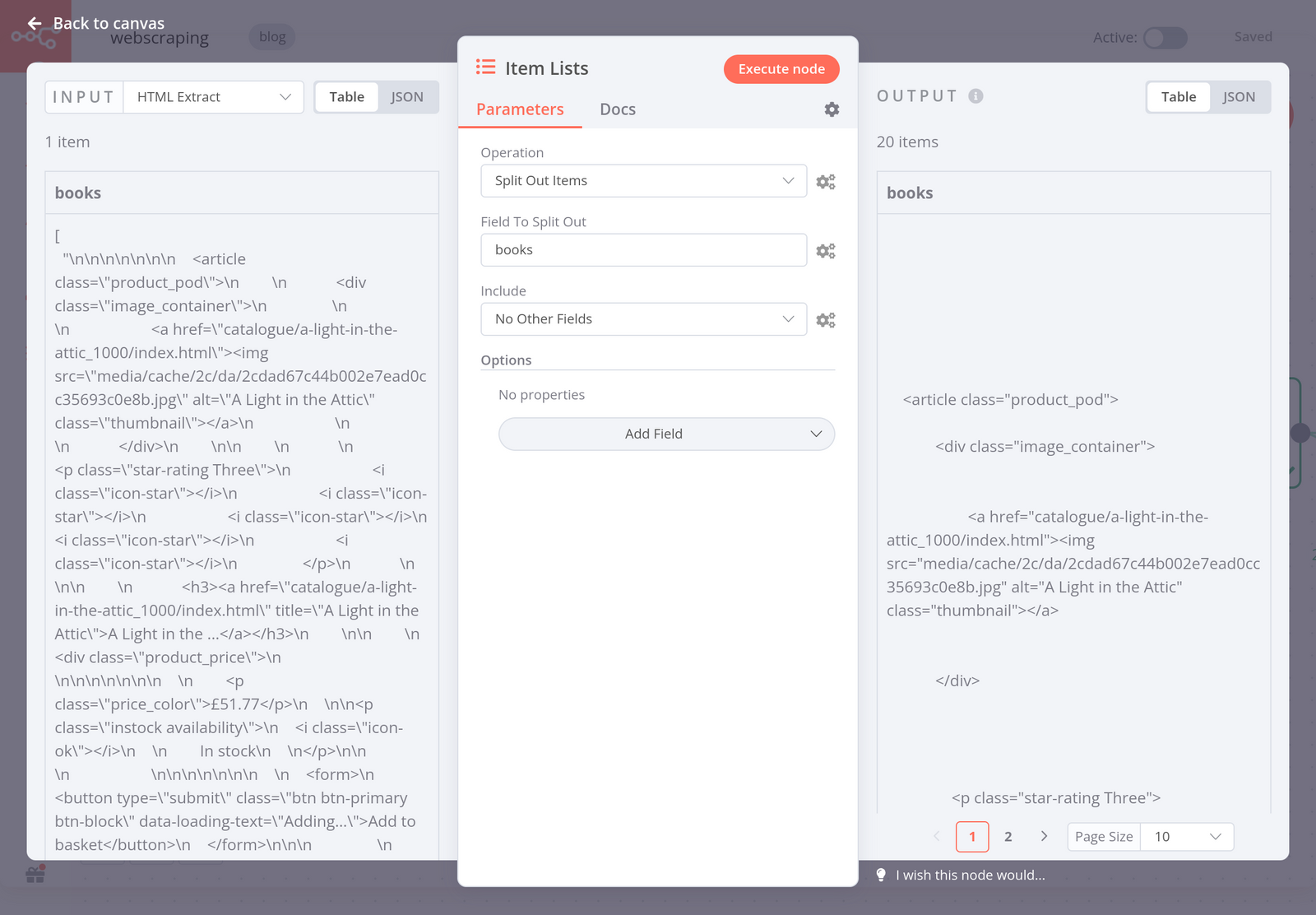
The HTML Extract node returns one item that contains the HTML code of all the books on the page. However, you need each book to be an item, so that you can extract each title and price. To do this, use the Item Lists node with the following parameters:
- Operation: Split Out Items
- Field To Split Out: books
This is the name of the key in the extraction value set in the previous HTML Extract node. - Include: No Other Fields
When you execute the node, the result should look like this:
Now that you have a list of 20 items (books), you need to extract the title and price from their HTML code. This part is similar to the previous step. To do this, use another HTML Extract node with the following parameters:
- Source Data: JSON
- JSON Property: books
- Extraction Values:
- Key: title
CSS Selector: h3
Return Value: Text - Key: price
CSS Selector: article > div.product_price > p.price_color
Return Value: Text
- Key: title
When you execute the node, the result should look like this:
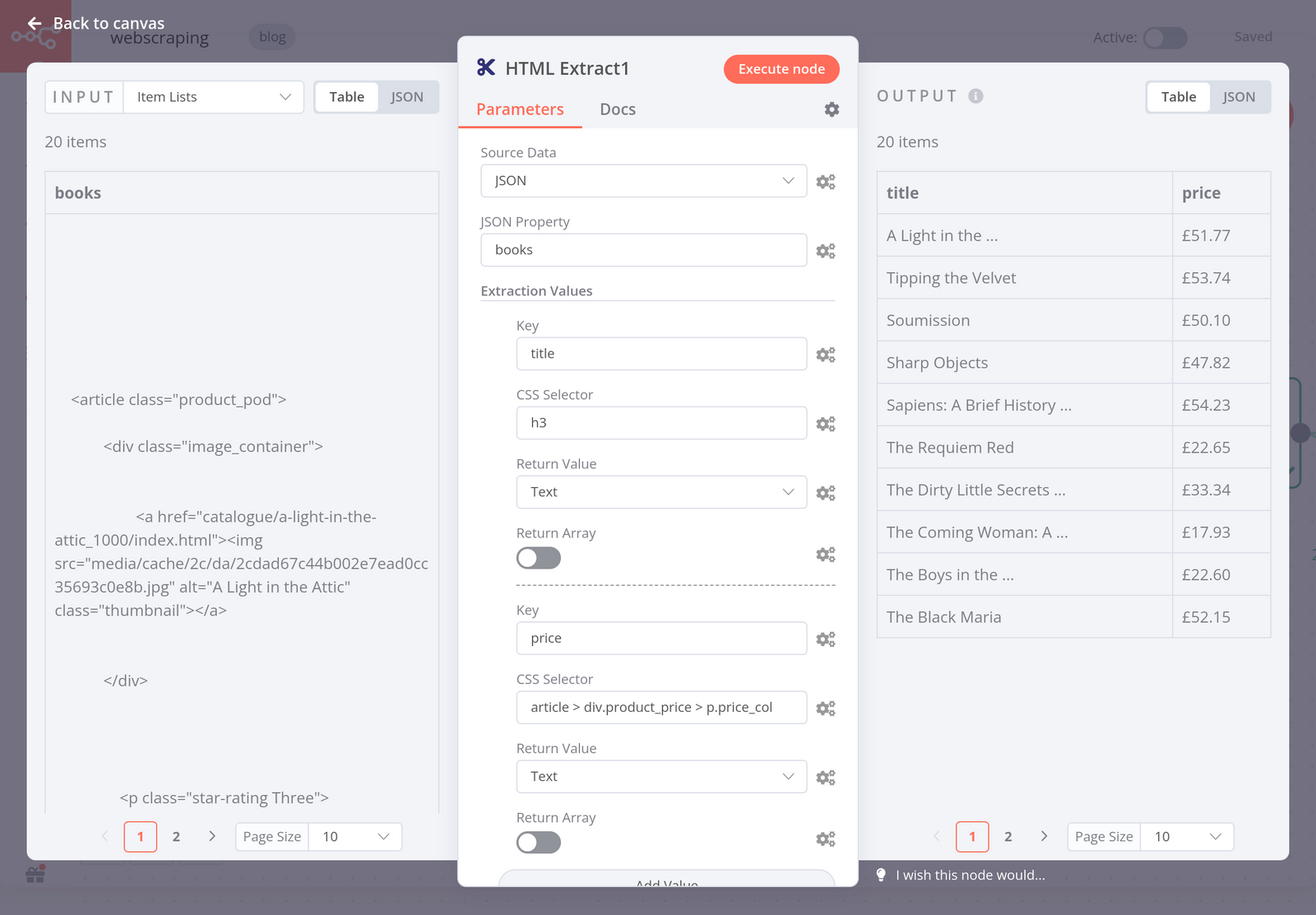
Step 3 - Ordering data
Now you have a nice table that contains the titles and prices of 20 books in store. Optionally, you can sort the books by their price in descending order. To do this, use another Item Lists node with the following parameters:
- Operation: Sort
- Type: Simple
- Fields To Sort By:
- Field Name: price
- Order: Descending
When you execute the node, the result should look like this:
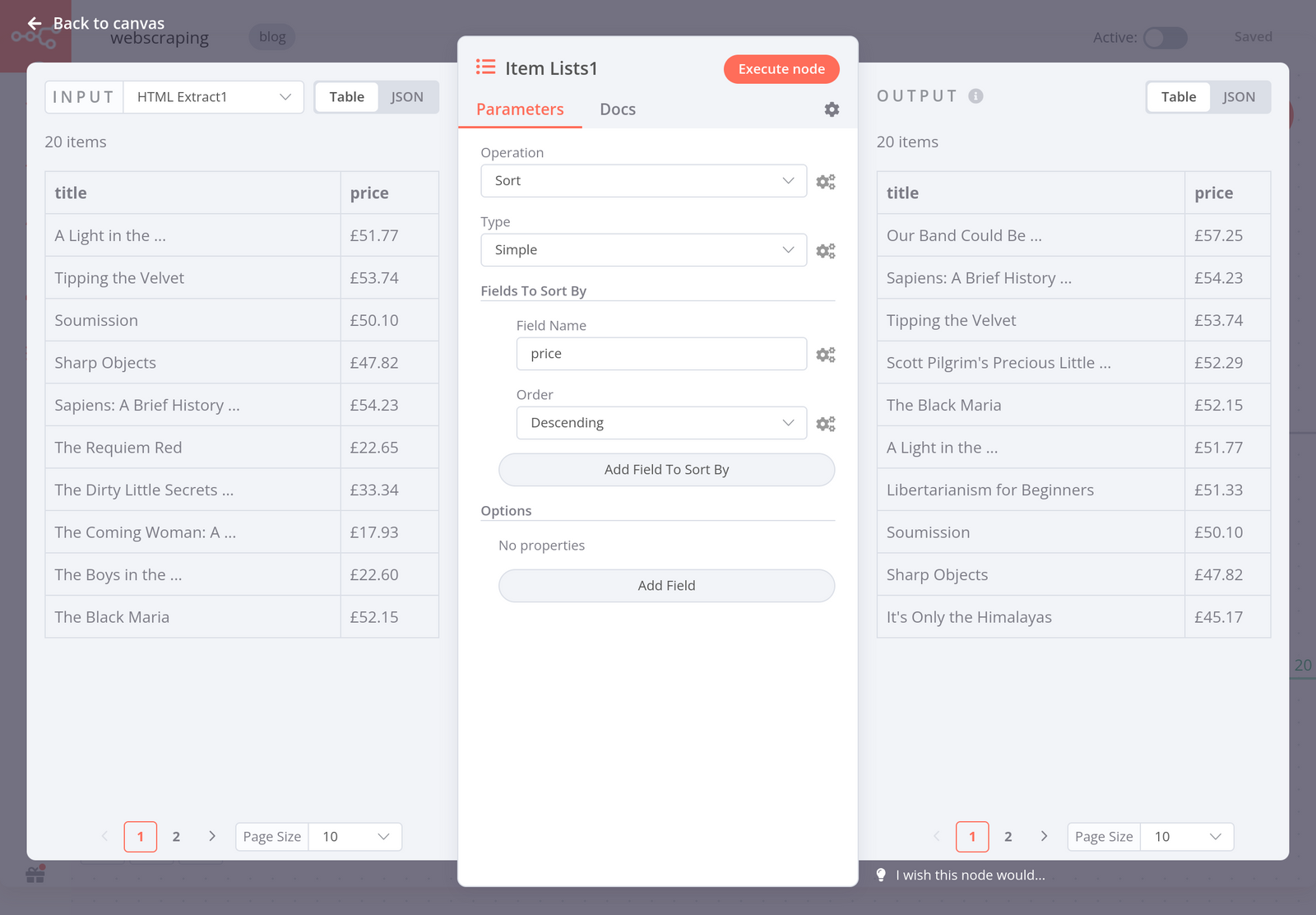
Step 4 - Writing the scraped data to a spreadsheet
Now that you scraped the data in a structured way, you’ll want to export it as a CSV file. To do this, use the Spreadsheet File node with the following parameters:
- Operation: Write to file
- File Format: CSV
- Binary Property: data
When you execute the node, the result should look like this:
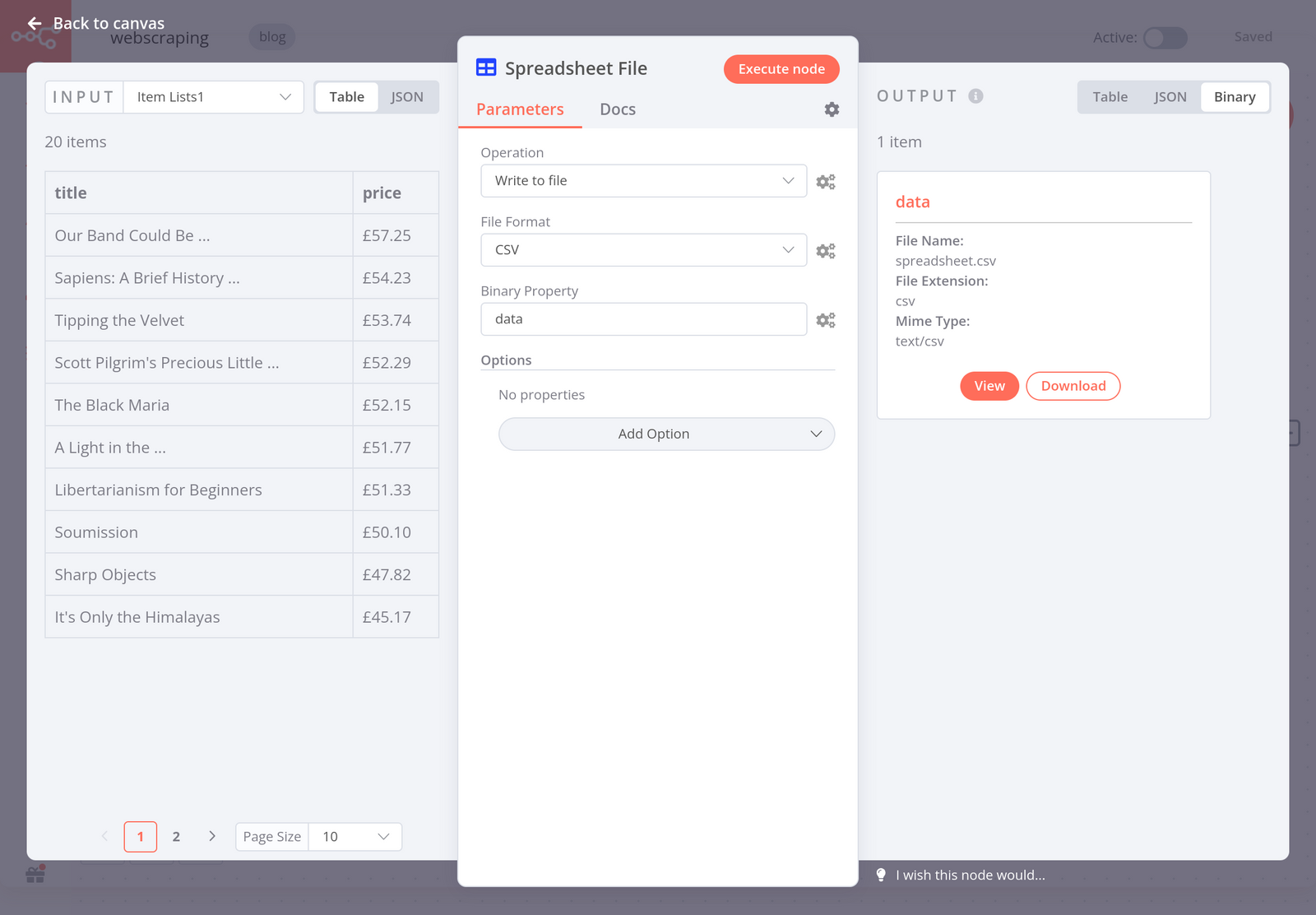
From here, you can download the CSV file directly to your computer.
Another option is to store the scraped data in a Google Sheet. You can do this using the Google Sheets node. The result of this node would look like this:
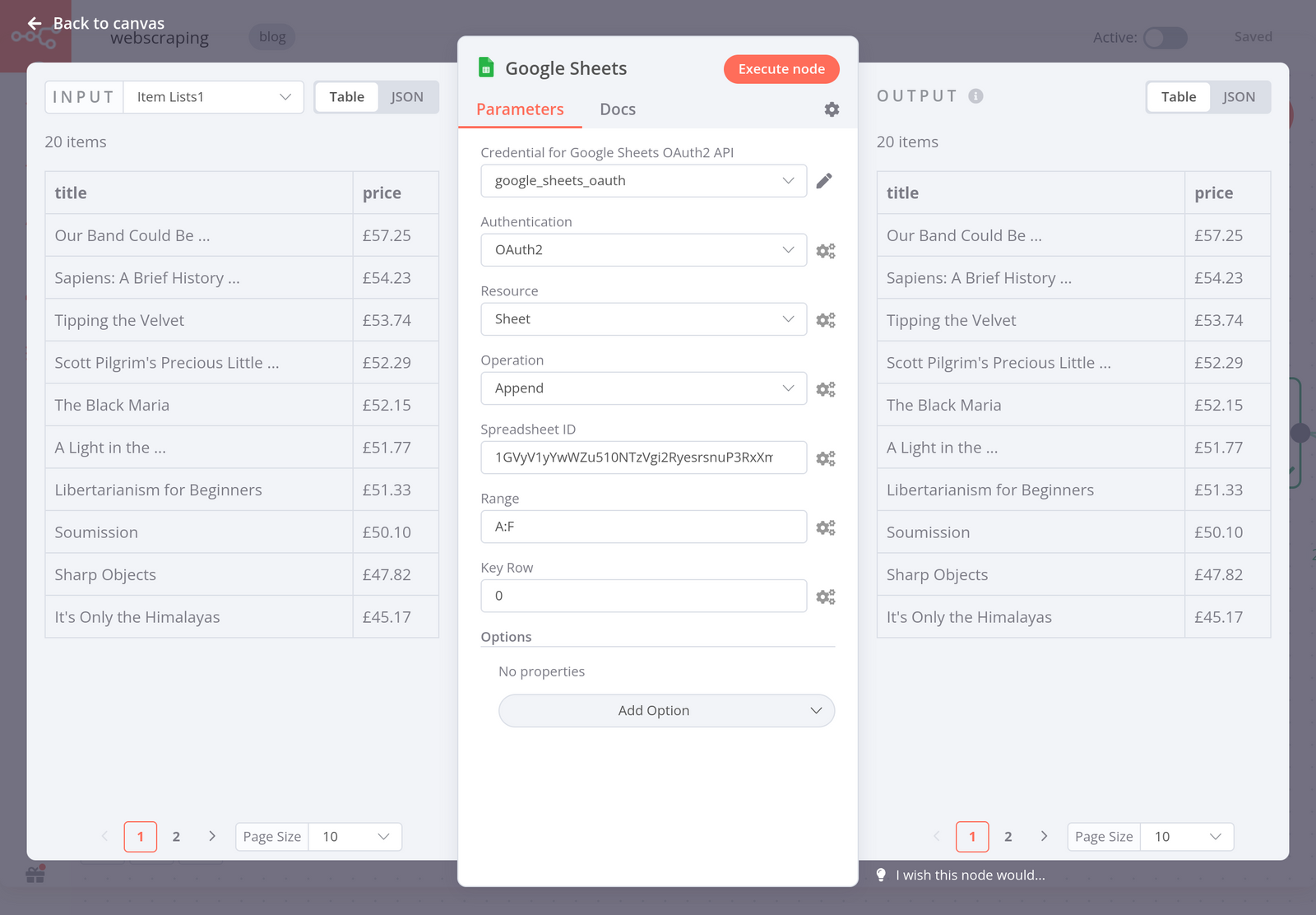
Step 5 - Sending the data set via email
Finally, you might want to send the CSV file with the scraped book data via email. To do this, use the Gmail node with the following parameters:
- Resource: Message
- Operation: Send
- Subject: bookstore csv (or any other subject line you’d like)
- Message: Hey, here’s the scraped data from the online bookstore website.
- To Email: the email address you want to send to
- Additional Fields > Attachments > Property: data
This is the name of the binary property set in the Spreadsheet File node.
When you execute the node, the result should look like this:
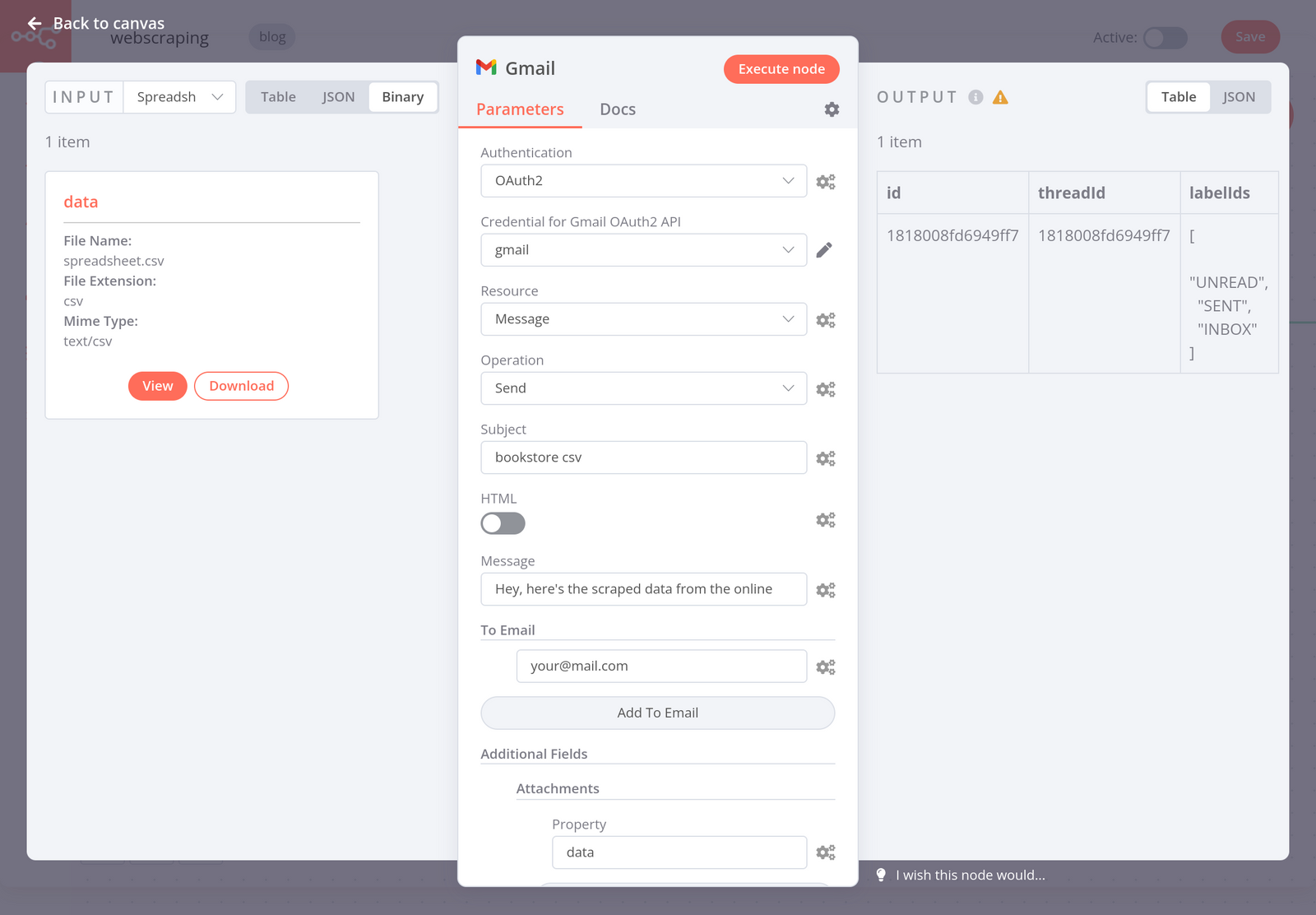
Now just check your inbox – you should receive an email with the CSV file!
What’s next?
Now you know the basics of web scraping: what it is, how it works, and what to keep in mind when scraping websites. You also learned how to build a no-code workflow that automatically scrapes data from an online store, stores in a spreadsheet, and emails it.
Here’s what you can do next:
- Check out a more complex workflow that scrapes data from a multi-page website, and read about the use case behind it.
- Check out the workflow page for more automation ideas.
- Subscribe to our newsletter to get the latest news around workflow automation with n8n.
- Join the community forum and follow us on Twitter.
This post was originally published on the n8n blog.